Java’nın geliştiricilere sağladığı en büyük konfor “bellek yönetimi” diyebiliriz. Java, kullanılmayan nesneleri temizlemek ve belleği boşaltmak için arka planda çalışan, Garbage Collector olarak adlandırılan otomatik bellek yönetimine sahiptir. Siz sadece değişkenleri bildirir, nesneleri oluşturur ve bu değişkenlere atarsınız ve yeri geldiğinde kullanırsınız gerisini Java halleder. C/C++ dillerinde program geliştirenler, memory leak olarak adlandırılan ve artık kullanılmayan başı boş nesnelerin kontrol edilmediğinde nelere mal olabileceğini iyi bilirler (performans ile ilgili problemler en iyimser kötü durumdur). Memory leak problemi Java’da neredeyse hiç oluşmaz (bazı bariz programcı hataları hariç).
Ancak elimizde zaten Garbage Collector gibi bir araç var düşüncesiyle bellek yönetimini tamamen ona bırakmak istenen bir durum değildir. Çünkü Java bu konuda tam bir garanti vermiyor. Garbage Collector için uygun olmayan birtakım nesneler olabiliyor. Özellikle is parcaciklari, büyük veri yığınları ve Streaming API gibi bellek sömüren şeylerle uğraşıyorsanız (Java’da bellek ile ilgili problemleri en çok bu API’yi kullandığımda yaşadım) Java’nın bellek yönetimi ile ilgili hususlarını bilmeniz gerekir. Eğer bellekle ilgili bir şeyler kötü gidiyorsa sonucunda bir OutOfMemoryError hatası almanız ve daha kötüsü bir memory leak ile karşılaşmanız yüksek ihtimaldir. Bu nedenle ölçeklenebilir bir şekilde çalışan, optimize edilmiş, yüksek performanslı uygulamalar geliştirmek ve bellekle ilgili sorunlarla karşılaşmamak için belleğin Java’da nasıl çalıştığı ve nasıl yönetildiği ile ilgili bilgi ve beceri sahibi olmak oldukça önemlidir.
Java’da belleğin genel olarak nasıl düzenlendiğine göz atarak başlayalım:
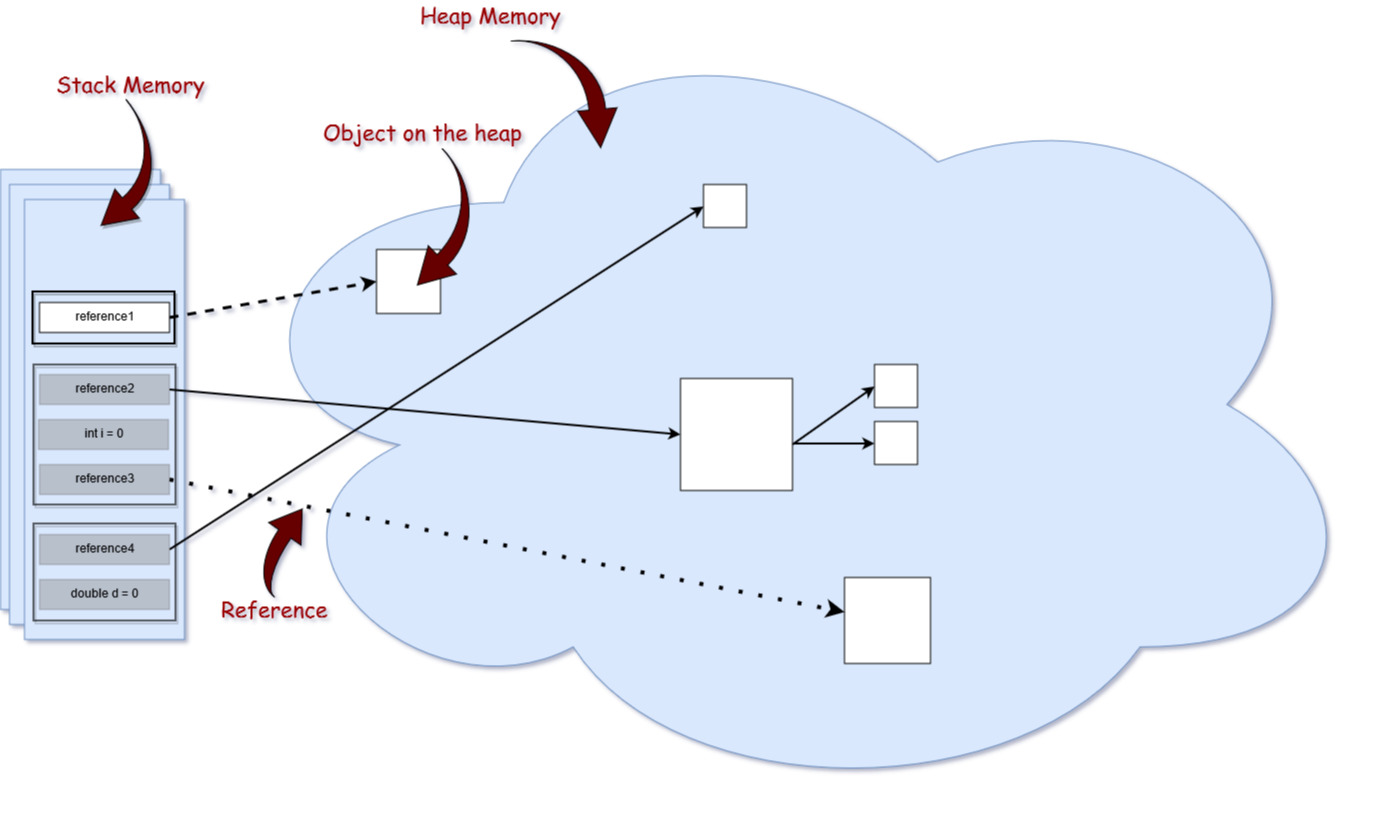
JVM, bir Java programının yürütülmesi sırasında kullanılan çeşitli çalışma zamanı (runtime) veri alanlarını tanımlar. Bazı alanlar JVM tarafından, bazıları ise programda kullanılan iş parçacıkları (thread) tarafından oluşturulur. Ancak, JVM tarafından oluşturulan bellek alanı yalnızca JVM’den çıkıldığında yok edilir. İş parçacıklarına ait veri alanları, iş parçacığı başlatıldığı sırada oluşturulur ve iş parçacığından çıkıldığında bu alanlar yok edilir.
Genel olarak, bellek iki büyük bölüme ayrılır: Stack ve Heap alanları. Heap alanı, Stack alanına kıyasla çok daha büyüktür.
Stack Bellek Alanı
Stack bellek alanında, heap alanındaki nesnelere ait referanslar ve ilkel veri türlerindeki (char, int, double, vs) veriler tutulmaktadır. Stack bellek alanı sabit veya dinamik boyutta olabilir. Stack bellek alanının boyutu, oluşturulduğunda bağımsız olarak seçilebilir ve bu alanın ardisik olması gerekmez.
Ayrıca stack alandaki değişkenler, kapsam (scope) olarak da adlandırılan belirli bir görünürlüğe sahiptir. Yalnızca etkin kapsamdaki nesneler kullanılabilir durumdadır. Mesela, global kapsamda herhangi bir değişkenimizin olmadığını ve yalnızca metotlarımızın içinde yerel değişkenlerimizin olduğunu varsayalım. Derleyici bir metodun gövdesini çalıştırdığında, stack alandaki nesnelerden yalnızca metodun gövdesi içinde olanlara erişebilir. Kapsam dışında olacakları için diğer metotların içindeki yerel değişkenlere erişemez. Metot tamamlanıp çağrıldığı noktaya geri dönüldüğünde, stack belleğin üstündeki bu metoda ait girdi pop edilir ve böylece etkin kapsam da değişir.
Her iş parçacığı için ayrı bir stack alanı tahsis edilir. Bu yüzden oluşturulan her iş parçacığı kendi stack bellek alanına sahip olur ve hiçbir iş parçacığı bir diğerinin stack bellek alanına erişemez.
Native Metot Stack Alanı
C stack alanı olarak da adlandırılan native metot stack alanları Java dilinde yazılmaz. Bu bellek, oluşturulduğunda her iş parçacığına özel olarak ayrılır ve sabit veya dinamik nitelikte olabilir.
Heap Bellek Alanı
Belleğin bu bölümü, nesnelerin kendisini tutar. Buradaki nesnelere stack alanındaki değişkenler tarafından referans verilir. Örneğin, aşağıdaki kod satırında neler olduğunu analiz edelim:
StringBuilder builder = new StringBuilder();
Burada new anahtar kelimesi ;
- Heap bellek alanı üzerinde yeterince boş alan olmasını sağlamaktan,
- Heap bellekte StringBuilder türünde bir nesne oluşturmaktan ve
- Stack bellek alanı üzerinde bulunan “builder” değişkeni ile bu nesneye referans vermekten sorumludur.
Çalışan her JVM prosesi için yalnızca bir heap bellek alanı tahsis edilir. Bu nedenle, heap bellek alanı kaç tane iş parçacığının çalıştığından bağımsız olarak tüm iş parçacıkları için belleğin paylaşılan bir parçasıdır. Heap alanı, JVM başlatıldığında oluşturulur ve uygulama çalışırken boyut olarak artabilir veya azalabilir. Heap boyutu –Xms parametresi kullanılarak belirtilebilir. Heap alanı, çöp toplama stratejisine bağlı olarak sabit veya değişken boyutta olabilir. Maksimum heap boyutu –Xmx parametresi kullanılarak ayarlanabilir. Maksimum boyutu varsayılan olarak 64 MB olarak ayarlanmıştır.
JVM’in heap alanı fiziksel olarak, her biri jenerasyon olarak da adlandırılan, iki bölüme ayrılır:
- Nursery/Young Generation Space (Yeni Doğan/Genç Nesil Nesne Alanı)
- Old Generation Space (Eski Nesil Nesne Alanı)
Genç nesil nesne alanı, heap alanının yeni oluşturulan nesnelerin tahsisi için ayrılmış bir parçasıdır. Bu alan dolduğunda, burada yeterince uzun süredir var olan tüm nesnelerin eski nesil nesne alanına taşındığı özel bir nesne toplama (young collection) prosesi çalıştırılarak çöp toplama işi yapılır. Böylece yeni nesne alanında daha fazla nesne tahsisi için yer açılmış olur. Eski nesne alanı dolduğunda ise eski nesne toplama işlemi olarak adlandırılan özel işlem çalıştırılarak buradaki nesneler bellekten tamamen kaldırılır.
Heap alanının genç nesil nesne alanı ve eski nesil nesne alanı olmak üzere ikiye ayrılmasının nedeni çoğu nesnenin geçici ve kısa ömürlü olmasıdır. Yeni nesil nesne toplama işlemi, hala var olan yeni tahsis edilmiş nesneleri bulacak ve onları genç nesil nesne alanından hızlı bir şekilde taşıyacak şekilde tasarlanmıştır. Genç nesil nesneleri toplama işlemi, eski nesil nesneleri toplama işleminden veya nursery alanı olmayan tek nesillik bir heap alanının çöp toplama işleminden çok daha hızlı çalışır. Bu çöp toplama modeline Minor GC (Minor Garbage Collection) adı verilir. Bu modelde nursery alanı üç bölüme ayrılmıştır: Bir adet Eden Bellek Alanı ve iki adet Survivor Bellek alanı (S0 ve S1).
Oracle’ın Hotspot‘tan önceki JVM uygulaması JRockit‘in R27.2.0 sonrası sürümlerinde, nursery alanının bir kısmı koruma alanı (keep area) olarak ayrılmıştır. Koruma alanında, nursery alanındaki en son tahsis edilen nesneler bulunur ve bir sonraki genç nesil nesneleri toplama işlemine kadar bu alanda çöp toplama prosesi çalışmaz. Buradaki nesneler, genç nesil nesne toplama işlemi başlamadan hemen önce tahsis edildikleri için eski nesil nesne alanına taşınmaları engellenmiş olur.
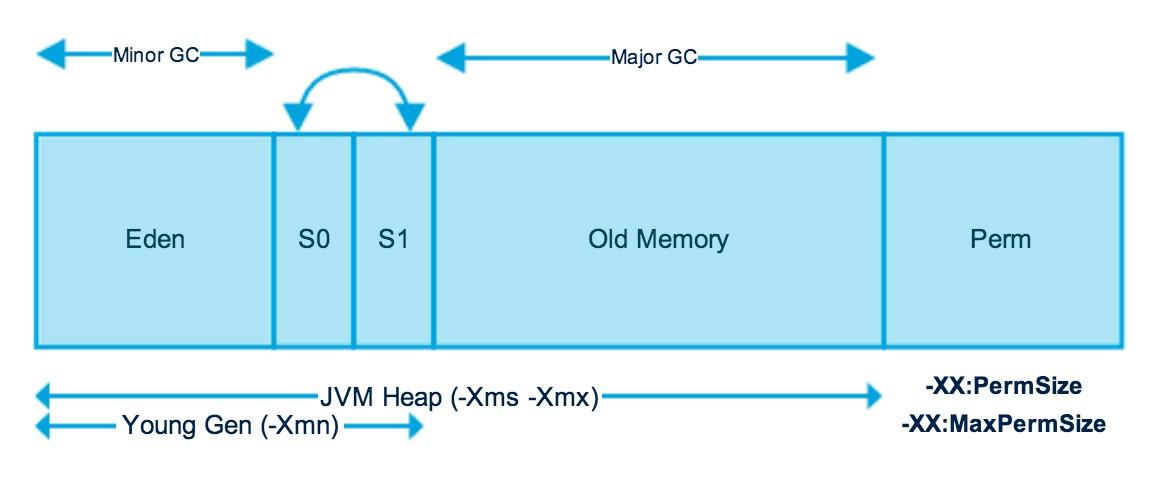
Nursery (Yeni Nesil) bellek alanı ile ilgili bazı önemli hususlar:
- Yeni oluşturulan nesnelerin çoğu Eden bellek alanında bulunur.
- Eden alanı nesnelerle dolduğunda, Minor GC işlemi gerçekleştirilir. Minor GC işleminden kurtulan tüm nesneler survivor (kurtulan) nesneler olarak adlandırılır ve survivor nesne alanlarından birine (S0 veya S1) taşınır.
- Minor GC ayrıca survivor nesneleri de kontrol eder ve onları diğer survivor alanına taşır. Yani belli bir anda, survivor alanlarından biri daima boştur.
- Buraya kadarki çöp toplama döngülerinden kurtulan nesneler, eski nesil bellek alanına taşınır. Bu amaçla genellikle, yeni nesil nesnelerin eski nesil alanına taşınmaya uygun hale gelmeden önceki ömrü için bir eşik değeri ayarlanır.
Eski nesil nesne alanı (Old Memory) dolduğunda burada çöp toplama işlemi yapılır. Bu işleme eski nesil nesneleri toplama işlemi denir. Eski nesil bellek alanı, Minor GC‘nin birçok nesne toplama döngüsünden kurtulan uzun ömürlü nesneleri içerir. Eski nesil bellekte çöp toplama işlemi, genellikle eski nesil bellek alanı dolduğunda gerçekleştirilir. Major GC olarak adlandırılan eski nesil nesnelerin toplanması işlemi genellikle daha uzun sürer.
Non-Heap (Heap Olmayan) Bellek Alanı
JVM, Non-Heap Bellek olarak adlandırılan heap harici bir belleğe sahiptir. JVM başladığında oluşturulur ve çalışma zamanı sabit havuzu (runtime constant pool), sınıflara ait değişkenler (field/attribute) ve metot verileri gibi her bir sınıf için oluşturulan yapıların, metotların ve yapıcı metotların kodunun yanı sıra dahili Stringleri de depolar. Non-heap belleğin varsayılan maksimum boyutu 64 MB’dir. Bu değer, komut satırında –XX:MaxPermSize parametresi kullanılarak değiştirilebilir (Java 8 ile birlikte Metaspace olmuştur).
Referans Türleri
Yukarıdaki ilk resimde temsili olarak gösterilen Java bellek yapısına yakından bakarsanız, yığındaki nesnelere yapılan referansları temsil eden okların aslında farklı türlerde olduğunu fark edeceksiniz. Bunun nedeni, Java programlama dilinde farklı türde referanslara sahip olmamızdır: güçlü (strong), zayıf (weak), yumuşak (soft) ve hayali (phantom) referanslar. Referans türleri arasındaki fark, heap alanı üzerindeki refere ettikleri nesnelerin farklı kriterler altında çöp toplamaya uygun olmasıdır. Her birine daha yakından bakalım.
1. Güçlü (Strong) Referans
Bu referans türü hepimizin alışık olduğu en bilindik referans türüdür. Yukarıdaki örnekte StringBuilder ile heap alanında bulunan bir nesneye güçlü bir referansımız mevcut. Heap alanındaki nesne, kendisine işaret eden güçlü bir referans varken veya güçlü referanslar zinciri aracılığıyla güçlü bir şekilde erişilebilir durumdayken çöp toplama sürecine dahil edilmez.
2. Zayıf (Weak) Referans
Basit bir ifadeyle, heap alanından bir nesneye yapılan zayıf bir referansın bir sonraki çöp toplama sürecinden sonra hayatta kalamaması muhtemeldir. Aşağıdaki örnekte zayıf bir referans oluşturulmuştur:
WeakReference<StringBuilder> ref = new WeakReference<>(new StringBuilder());
Zayıf referanslar için güzel bir kullanım örneği, önbelleğe alma (caching) senaryolarıdır. Örneğin bazı veriler aldığınızı ve bunların bellekte de saklanmasını istediğinizi düşünün – aynı veriler tekrar tekrar istenebilir. Ancak, öte yandan da, bu verilerin istenip istenmeyeceğinden veya ne zaman tekrar isteneceğinden emin değilsiniz. Böylece ona zayıf bir referans tutabilirsiniz ve çöp toplayıcının çalışması durumunda, nesnenizi heap alanından yok edebilir. Bu nedenle, bir süre sonra başvurduğunuz nesneyi almak isterseniz null değer alabilirsiniz. Önbelleğe alma senaryoları için güzel bir uygulama, WeakHashMap<K, V> koleksiyonudur. Java API’sinde WeakHashMap sınıfını açarsak, girdilerinin (entry) aslında WeakReference sınıfını genişlettiğini ve ref alanını Map’in key’i olarak kullandığını görürüz:
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
V value;
WeakHashMap‘ten bir anahtar (key) çöp toplama sürecine dahil olduğunda, girdinin (entry) tamamı Map’ten kaldırılır.
3. Yumuşak (Soft) Referans
Bu tür referanslar, yalnızca uygulamamızın belleği azaldığında çöp olarak toplanacağından, belleğe daha duyarlı senaryolar için kullanılır. Bu nedenle, biraz alan boşaltmak için kritik bir ihtiyaç olmadığı sürece, çöp toplayıcı yumuşak bir şekilde erişilebilen nesnelere dokunmayacaktır. Java’nın referans belgelerinde de belirtildiği üzere, Java, bir OutOfMemoryError göndermeden önce tüm yumuşak referanslı nesnelerin temizlenmesini garanti eder.
Yumuşak referanslar da zayıf referanslara benzer şekilde oluşturulur. Aşağıdaki kod parçasında bunun bir örneği verilmiştir:
SoftReference<StringBuilder> reference = new SoftReference<>(new StringBuilder());
4. Hayalet (Phantom) Referans
Nesnelerin artık canlı olmadığından emin olduğumuz için ölüm sonrası temizleme eylemlerini planlamak için kullanılır. Bu tür referansların .get() yöntemi her zaman null döndüreceğinden, yalnızca bir referans kuyruğuyla kullanılır. Bu tür referansların, finalizerlara tercih edilebileceği kabul edilir.
String’lere Referans Verme
Java, String türü nesnelere biraz farklı davranır. String’ler değişmez (immutable) yapıda veri türleridir. Yani bir string nesnesine yaptığınız her bir işlemde, heap üzerinde aslında başka bir nesne oluşturulur. Java stringler için bellekteki bir string havuzunu (string pool) yönetir. Bu, Java’nın stringleri mümkün olduğunda sakladığı ve yeniden kullandığı anlamına gelmektedir. Bu çoğunlukla stringlerin değişmez (literal) değerleri için geçerlidir. Mesela:
String localPrefix = "297"; //1
String prefix = "297"; //2
if (prefix == localPrefix)
{
System.out.println("Strings are equal" );
}
else
{
System.out.println("Strings are different");
}
Yukarıdaki kod parçası çalıştırıldığında
Strings are equal
Sonucunu ekrana basacaktır.
Bu nedenle, String türündeki iki referans karşılaştırıldıktan sonra, bunların aslında heap alanı üzerindeki aynı nesneleri gösterdiği ortaya çıkar. Ancak bu, hesaplanan Stringler için geçerli değildir. Yukarıdaki kodun //1 ile gösterilen satırında aşağıdaki değişikliğin olduğunu varsayalım.
String localPrefix = new Integer(297).toString(); //1
Bu değişiklikle birlikte kodumuz aşağıdaki çıktıyı üretecektir:
Strings are different
Bu durumda aslında heap üzerinde iki farklı nesnemiz olduğunu görüyoruz. Hesaplanan String’in oldukça sık kullanılacağını düşünürsek, hesaplanan string’in sonuna .intern() yöntemini ekleyerek JVM’i bu sonucu string havuzuna (string pool) eklemeye zorlayabiliriz:
String localPrefix = new Integer(297).toString().intern(); //1
Yukarıdaki değişikliğin eklenmesi aşağıdaki çıktıyı oluşturur:
Strings are equal
Çöp Toplama Süreci
Daha önce bahsettiğimiz gibi, stack alanındaki bir değişkenin heap alanından bir nesneye tuttuğu referansın türüne bağlı olarak, bu nesne belirli bir zamanda çöp toplayıcı için uygun hale gelir.
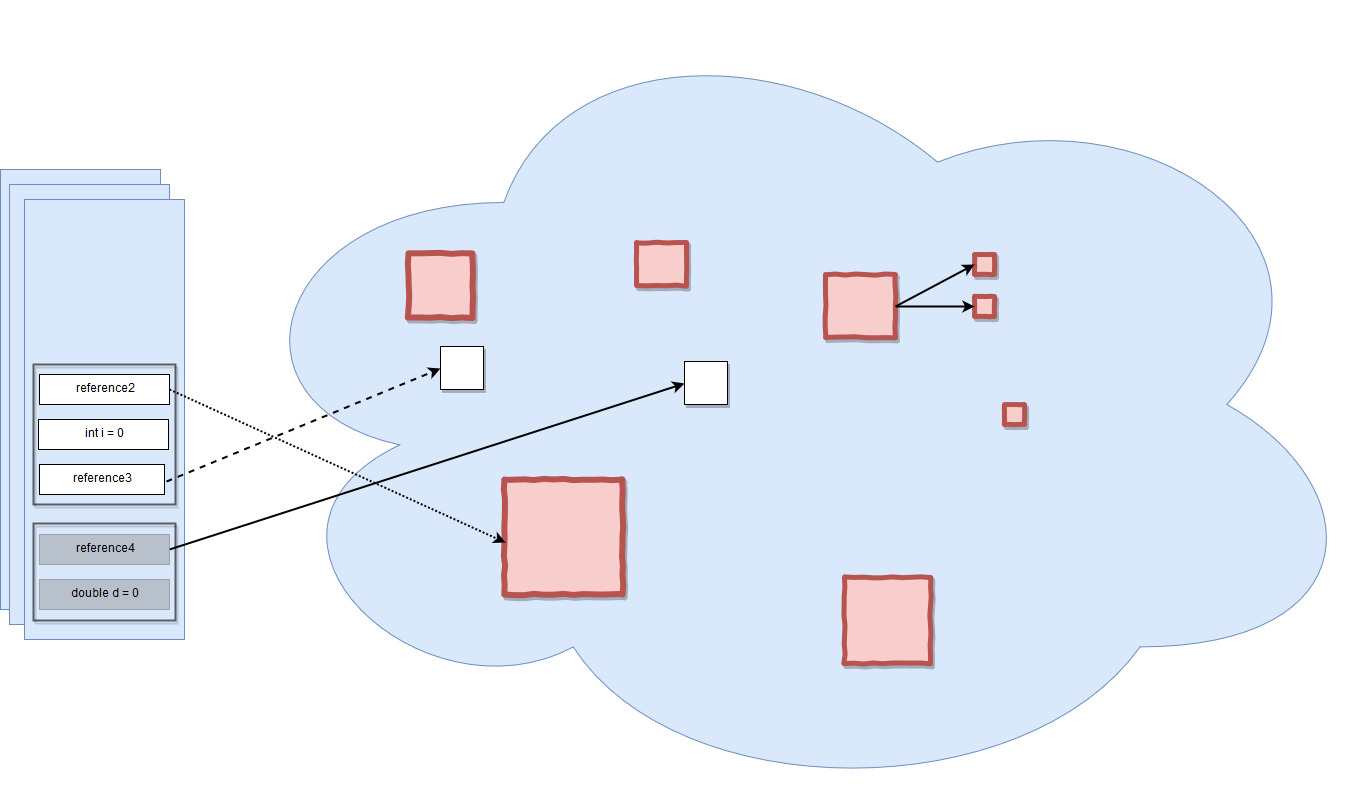
Örneğin, yukarıdaki resimde görülen kırmızı olan tüm nesneler çöp toplayıcı tarafından toplanmaya uygundur. Bununla birlikte heap alanı üzerinde, diğer nesnelere güçlü referansları olan başka bir nesne olduğunu görüyoruz (örneğin, öğelerine referansları olan bir liste veya referans verilen iki tip alanına sahip bir nesne olabilir). Ancak stack alanından gelen referans kaybolduğu için artık ona erişilemez, bu yüzden o da çöptür.
Java’nın en iyi özelliklerinden biri otomatik çöp toplamadır. Çöp Toplayıcı, bellekteki tüm nesnelere bakan ve programın herhangi bir bölümü tarafından başvurulmayan nesneleri bulan arka planda çalışan programdır. Tüm bu başvurulmamış nesneler silinir ve diğer nesnelere tahsis edilmek üzere alan geri kazanılır. Çöp toplamanın temel yollarından biri üç adımdan oluşur:
İşaretleme: Bu, çöp toplayıcının hangi nesnelerin kullanımda olduğunu ve hangilerinin kullanımda olmadığını belirlediği ilk adımdır.
Normal Silme: Çöp toplayıcı kullanılmayan nesneleri kaldırır ve diğer nesnelere ayrılacak boş alanı geri alır.
Sıkıştırarak silme: Daha iyi performans için, kullanılmayan nesneleri sildikten sonra, hayatta kalan tüm nesneler bir arada olacak şekilde taşınabilir. Bu işlem, yeni nesnelere bellek ayırma performansını artıracaktır.
Ayrıntılara inmeden önce şu üç husustan bahsetmemiz gerekiyor:
- Bu işlem Java tarafından otomatik olarak tetiklenir ve bu işlemin ne zaman başlatılacağı veya başlatılıp başlatılmayacağı Java’ya bağlıdır.
- Çöp toplama süreci aslında pahalı bir süreçtir. Çöp toplayıcı çalıştığında, uygulamanızdaki tüm iş parçacıkları duraklatılır (daha sonra bahsedeceğimiz GC türüne bağlı olarak).
- Bu aslında çöp toplama ve belleği boşaltmaktan daha karmaşık bir işlemdir.
Java, çöp toplayıcının ne zaman çalıştırılacağına karar verse bile, açıkça System.gc()‘yi çağırabilir ve bu kod satırını yürütürken çöp toplayıcının çalışmasını bekleyebilirsiniz, değil mi? Aslında hayır. Bu yanlış bir varsayımdır. Biz sadece Java’dan çöp toplayıcıyı çalıştırmasını isteyebiliriz, ancak bunu yapıp yapmamak yine ona bağlıdır. Bu yüzden, System.gc() öğesinin açık şekilde çağrılması önerilmez.
Bu oldukça karmaşık bir süreç olduğundan ve performansınızı etkileyebileceğinden akıllı bir şekilde uygulanmaktadır. Bunun için “İşaretle ve Süpür” (Mark and Sweep) olarak adlandırılan işlem kullanılır. Java, stack alanındaki değişkenleri analiz eder ve canlı tutulması gereken tüm nesneleri “işaretler”. Ardından, kullanılmayan tüm nesneleri heap alanından kaldırır.
Yani, Java aslında herhangi bir çöp toplamaz. Ne kadar çok çöp varsa ve nesneler ne kadar az canlı olarak işaretlenirse, süreç o kadar hızlı olur. Bunu daha da optimize etmek için, heap belleği birden fazla parçadan oluşturulmuştur. Java JDK ile birlikte gelen bir araç olan Java VisualVM ile bellek kullanımını ve diğer faydalı şeyleri görselleştirebiliriz. Yapmamız gereken tek şey, belleğin gerçekte nasıl yapılandırıldığını görmemizi sağlayan Visual GC adlı eklentiyi yüklemektir. Burada biraz yakınlaşalım ve belleğin yapısını daha iyi anlamak için büyük resmi parçalayalım:
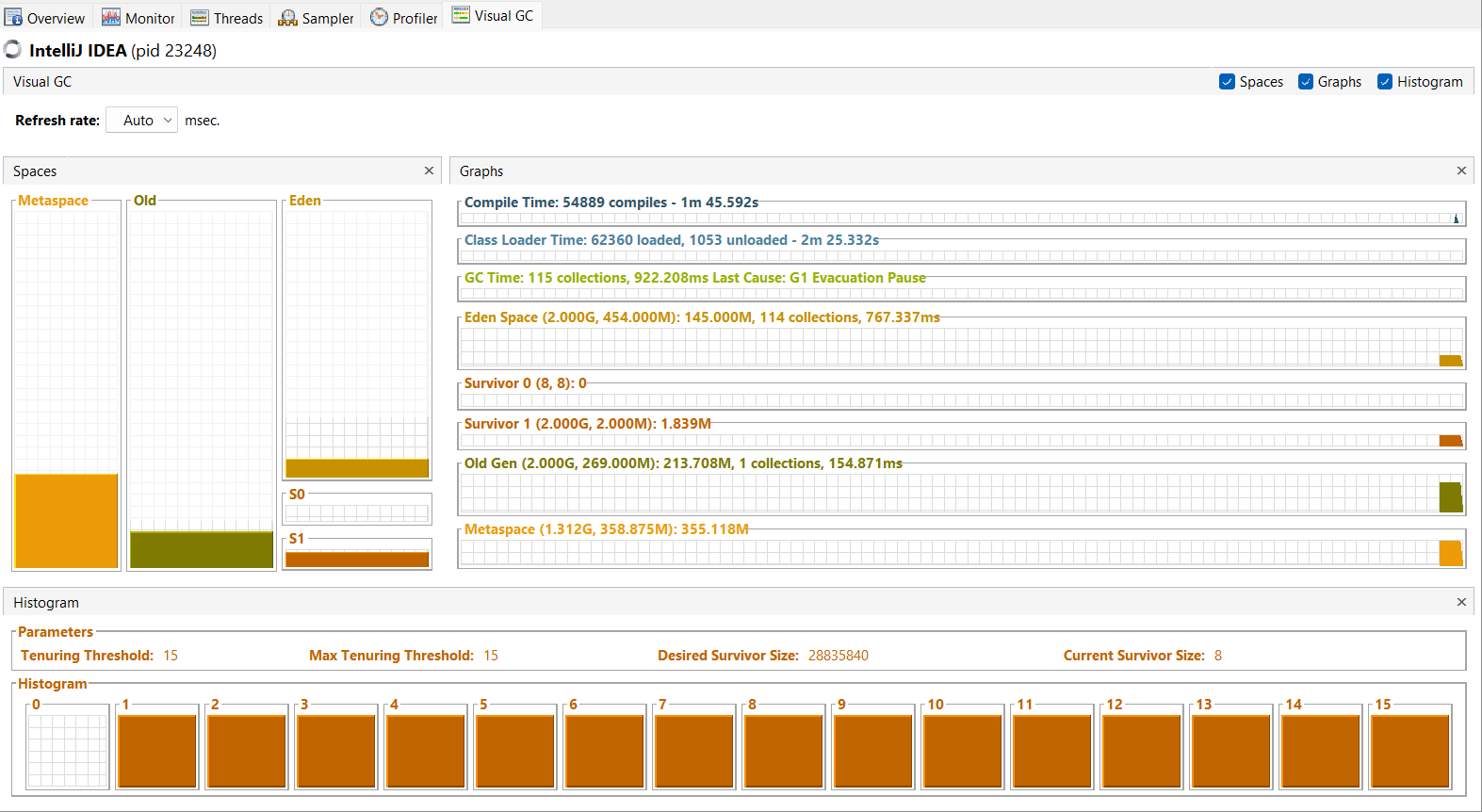
Bir nesne oluşturulduğunda, Eden alanında bu nesne için bir yer tahsis edilir. Eden alanı o kadar büyük olmadığı için oldukça hızlı bir şekilde dolar. Çöp toplayıcı, Eden alanında çalışır ve nesneleri canlı olarak işaretler.
Bir nesne çöp toplama işleminden kurtulduktan sonra, survival S0 olarak adlandırılan bir alana taşınır. Çöp toplayıcı ikinci kez Eden alanında çalıştığında, hayatta kalan tüm nesneleri S1 alanına taşır. Ayrıca, o anda S0 üzerinde olan her şey S1 alanına taşınır.
Bir nesne X tur çöp toplama sonucunda hayatta kalırsa (X, JVM uygulamasına bağlıdır, bu örnekte 8’dir), büyük olasılıkla sonsuza kadar hayatta kalacaktır ve Old (Eski nesil) nesne alanına taşınır.
Buraya kadar söylenenlerin hepsini göz önüne alarak çöp toplayıcı grafiğine bakacak olursak, çöp toplayıcı her çalıştığında nesnelerin survival (S0/S1) alanına geçtiğini ve Eden alanında yer açıldığını görebiliriz. Eski nesil nesne alanı üzerinde de çöp toplama işlemi yapılabilir ama Eden alanına göre belleğin daha büyük bir parçası olduğu için Eden alanındaki kadar sık olmaz. Metaspace, uygulamanin bellege yüklenen sınıfları hakkındaki meta verileri JVM’de depolamak için kullanılır.
Burada aslında yeni surum bir Java uygulamasının bellek yapısını göstermektedir. Java 8’den önce, belleğin yapısı biraz daha farklıydı. Metaspace, PermGen alanı olarak adlandırılıyordu. Örneğin, Java 6’da bu alanda aynı zamanda string pool da tutuluyordu. Bu nedenle, Java 6 uygulamanızda çok fazla string varsa, çökebilirdi.
İşaretle ve Süpür Modeli
JVM, tüm heap alanının çöp toplama işlemini gerçekleştirmek için işaretle ve süpür çöp toplama modelini kullanır. İşaretle ve süpür çöp toplama, işaretleme aşaması ve süpürme aşaması olmak üzere iki aşamadan oluşur.
İşaretleme aşamasında, Java iş parçacıklarından (threads), yerel işleyicilerden (native handlers) ve diğer kök kaynaklardan erişilebilen tüm nesnelerin yanı sıra bu nesnelerden erişilebilen nesneler de canlı olarak işaretlenir. Bu işlem hala kullanılan tüm nesneleri tanımlar ve işaretler ve gerisi çöp olarak kabul edilebilir.
Süpürme aşamasında, canlı nesneler arasındaki boşlukları bulmak için heap üzerinde gezinilir. Bu boşluklar boş bir listeye kaydedilir ve yeni nesne tahsisi için kullanılabilir hale getirilir.
Çöp Toplayıcı Çeşitleri
Uygulamalarımızda kullanabileceğimiz beş çeşit çöp toplama türü bulunmaktadır. Uygulama için çöp toplama stratejisini etkinleştirmek için sadece JVM anahtarını kullanmamız gerekiyor. Varsayılan olarak Java, temel alınan donanıma göre kullanılacak çöp toplayıcı türünü seçer.
1. Serial GC (-XX:+UseSerialGC) : Tek iş parçacıklı (thread) toplayıcıdır. Çoğunlukla küçük veri kullanımı olan küçük uygulamalar için geçerlidir. -XX:+UseSerialGC komut satırı seçeneği belirtilerek etkinleştirilebilir.
2. Paralel GC (-XX:+UseParallelGC) : Adından da anlaşılacağı üzere, Seri ve Paralel çöp toplama işlemi arasındaki fark, Paralel GC’nin çöp toplama işlemini gerçekleştirmek için birden fazla iş parçacığını (thread) kullanmasıdır. Bu GC türü, verimli toplayıcı (throughput collector) olarak da bilinir. Komut satırından -XX:+UseParallelGC seçeneği açıkça belirtilerek etkinleştirilebilir.
3. Paralel Eski GC (-XX:+UseParallelOldGC) : Hem genç nesil hem de eski nesil nesne alanından çöp toplamak için birden fazla iş parçacığı (thread) kullanması dışında Paralel GC ile aynıdır. Komut satırından -XX:+UseParallelOldGC seçeneği verilerek etkinleştirilebilir.
4. Eşzamanlı İşaretle Süpür (CMS) Toplayıcı (-XX:+UseConcMarkSweepGC) : CMS aynı zamanda eşzamanlı düşük duraklatmalı toplayıcı olarak da adlandırılır. Eski nesil nesne alanı için çöp toplama işini yapar. CMS toplayıcısı, çöp toplama işlerinin çoğunu uygulama iş parçacıkları içinde eş zamanlı olarak yaparak çöp toplama nedeniyle oluşan duraklamaları en aza indirmeye çalışır. Genç nesildeki CMS toplayıcısı, paralel toplayıcıyla aynı algoritmayı kullanır. Bu çöp toplayıcı, daha uzun duraklama sürelerini göze alamayacağımız hassas uygulamalar için uygundur. -XX:ParallelCMSThreads=n JVM seçeneğini kullanarak CMS toplayıcıdaki iş parçacığı sayısını sınırlayabiliriz. CMS toplayıcıyı etkinleştirmek için -XX:+UseConcMarkSweepGC parametresi kullanılır.
G1 (Çöp Önceli) Çöp Toplayıcı (-XX:+UseG1GC) : Makul bir uygulama duraklama süresi sunan yüksek verimli GC türüdür. -XX:+UseG1GC komut satırı seçeneği ile etkinleştirilir. Çöp Önceli veya G1 Çöp Toplayıcı, Java 7’den itibaren JVM’de vardır ve uzun vadeli hedefi CMS toplayıcısının yerini almaktır. G1 toplayıcı paralel, eşzamanlı ve artımlı olarak calisan kompakt ve düşük duraklamalı bir çöp toplayıcıdır. G1 toplayıcı diğer toplayıcılar gibi çalışmaz ve yeni ve eski nesil nesne alanı kavramı yoktur. Yığın alanını birden çok eşit boyutlu yığın bölgesine böler. Bu çöp toplayıcı çağrıldığında, önce daha az canlı nesne bulunan bölgeyi toplar, bu nedenle adına “Çöp Önceli” denilmiştir. G1 Çöp toplayıcıyı etkinleştirmek için -XX:+UseG1GC komut satırı parametresi kullanılır.
G1 çöp toplayıcısının, uzun vadede Eşzamanlı İşaretle Süpür (CMS) Toplayıcısının yerine geçmesi planlanmaktadır. CMS ile karşılaştırdığımızda, G1 Toplayıcısını daha iyi bir çözüm haline getiren bir takım farklılıklar olduğunu görürüz. Bunlardan ilki, bu toplayıcının bir sıkıştırma toplayıcısı olmasıdır. G1, nesne tahsisatı için kullanılacak serbest listelerin kullanılmasını önlemek için yeterince sıkıştırır ve bu listelerin yerine bölgeleri kullanır. Böylece, toplayıcı önemli ölçüde basitleşir ve potansiyel parçalanma sorunlarını çoğunlukla ortadan kaldırır. Ayrıca, G1 toplayıcısı, CMS toplayıcısından daha öngörülebilir çöp toplama duraklamaları sunar ve kullanıcıların istenen duraklatma hedeflerini belirlemelerine olanak tanır.
Java 8’de, G1 toplayıcısı, String Deduplication olarak bilinen bir optimizasyonla birlikte gelir. GC’nin heap alanı boyunca birden çok olan stringleri tanımlamasına ve heap alanda birden çok kopya olmaması için bunları aynı dahili char[] dizisine işaret etmesine olanak tanır. Bu özellik komut satırından -XX:+UseStringDeduplication JVM seçeneği kullanılarak etkinleştirilebilir.
G1, JDK 9’daki varsayılan çöp toplayıcıdır.
Kullanım Durumu
- Java heap alanının %50’den fazlası canlı verilerle doluysa.
- Nesne tahsisat oranı veya yükseltme oranı büyük ölçüde değişiyorsa.
- İstenmeyen uzunlukta çöp toplama veya sıkıştırma duraklamaları oluyorsa (0,5 ila 1 saniyeden daha uzun)
Bellek Kullanımının ve Çöp Toplayıcı Etkinliğinin İzlenmesi
Java uygulamalarındaki kararsızlığın ve yanıt vermemenin nedeni genellikle bellek yetersizliğidir. Bu nedenle, hem kararlılık hem de performans sağlamak için çöp toplama sürecinin yanıt süresi ve bellek kullanımı üzerindeki etkisini izlememiz gerekir. Ancak, bu iki öğe tek başına uygulama yanıt süresinin çöp toplama işleminden etkilenip etkilenmediğini söylemediğinden, bellek kullanımını ve çöp toplama sürelerini izlemek yeterli değildir. Yalnızca GC gecikmeleri yanıt süresini doğrudan etkiler ve bir GC uygulamayla eşzamanlı olarak da çalışabilir. Bu nedenle, çöp toplama işleminin neden olduğu gecikmeleri uygulamanın yanıt süresi ile ilişkilendirmemiz gerekiyor. Buna dayanarak aşağıdakileri izlememiz gerekir:
- Farklı bellek havuzlarının kullanımı (Eden, Survivor ve eski nesil). Bellek yetersizliği, artan GC etkinliğinin bir numaralı nedenidir.
- Çöp toplamaya rağmen genel bellek kullanımı sürekli artıyorsa, kaçınılmaz olarak bellek yetersizliğine yol açacak bir bellek sızıntısı vardır. Bu durumda, bir bellek yığını analizi gereklidir.
- Genç nesil koleksiyonların sayısı, kayıp oranı (nesne tahsis oranı) ile ilgili bilgi sağlar. Sayı ne kadar yüksek olursa, o kadar fazla nesne tahsis edilir. Çok sayıda genç koleksiyon, yanıt süresi sorununun ve büyüyen eski nesil (old) nesnenin nedeni olabilir (çünkü genç nesil artık nesnelerin miktarıyla baş edemez)
jstat
jstat yardımcı programı, çalışan uygulamaların performansı ve kaynak tüketimi hakkında bilgi sağlamak için Java HotSpot VM’deki yerleşik araçları kullanır. Araç, performans sorunlarını ve özellikle heap boyutlandırma ve çöp toplama ile ilgili sorunları tanılarken kullanılabilir. jstat yardımcı programı, JVM’in herhangi bir özel seçenekle başlatılmasını gerektirmez. Java HotSpot VM’deki dahili araçlar varsayılan olarak etkindir. Bu yardımcı program, tüm işletim sistemleri için JDK kurulumlarinda bulunur. jstat yardımcı programı, hedef prosesi tanımlamak için sanal makine tanımlayıcısını (VMID) kullanır.
JVM Heap bellek kullanımını öğrenmek için jstat komutunun gc seçeneğiyle kullanımı:
<JAVA_HOME>/bin/jstat –gc <JAVA_PID>

jstat‘ın verdiği çıktıda yer alan sütunların açıklamaları şöyledir:
S0C: Survivor 0 alanın mevcut kapasitesi (KB)
S1C: Survivor 1 alanının mevcut kapasitesi (KB)
S0U: Survivor 0 alanının kullanımı (KB)
S1U: Survivor 1 alanının kullanımı (KB)
EC: Eden (Yeni nesne) alanı mevcut kapasitesi (KB)
EU: Eden (Yeni nesne) alanının kullanımı (KB)
OC: Old (Eski nesne) alanının mevcut kapasitesi (KB)
OU: Old (Eski nesne) alanının kullanımı (KB)
MC: Metaspace kapasitesi (KB)
MU: Metaspace kullanımı (KB)
CCSC: Sıkıştırılmış sınıf alanı kapasitesi (KB)
CCSU: Sıkıştırılmış sınıf alanının kullanımı (KB)
YGC: Eden (Yeni nesne) çöp toplama olaylarının sayısı
TGCT: Eden (Yeni nesne) çöp toplama süresi
FGC: Full GC (Tam çöp toplama) olaylarının sayısı
FGCT: Full GC (Tam çöp toplama) süresi
GCT: Toplam çöp toplama süresi
jmap
jmap yardımcı programı, çalışan bir JVM veya çekirdek dosya için bellekle ilgili istatistikleri yazdırır. JDK 8 ile birlikte, JVM ve Java uygulamalarıyla ilgili sorunları teşhis etmek amacıyla Java Mission Control, Java Flight Recorder ve jcmd yardımcı programları gelmiştir. Gelişmiş tanılama ve performans kayıplarını önlemek için jmap yardımcı programı yerine en son yardımcı program olan jcmd‘nin kullanılması önerilir.
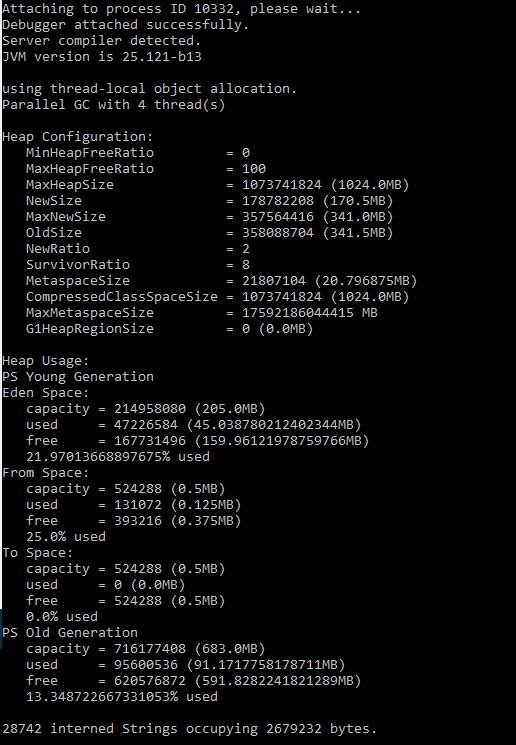
Aşağıdaki Java heap bilgilerini elde etmek için –heap seçeneği kullanılabilir:
- GC algoritmasının adı (örneğin, paralel GC) ve algoritmaya özgü ayrıntılar (paralel GC için iş parçacığı sayısı gibi) dahil olmak üzere GC algoritmasına özgü bilgiler.
- Komut satırı seçenekleri olarak belirtilmiş veya makine yapılandırmasına bağlı olarak VM tarafından seçilmiş olabilecek yığın yapılandırması.
- Heap kullanım özeti: Her nesil (heap’in alanı) için araç toplam yığın kapasitesini, kullanımdaki belleği ve kullanılabilir boş belleği yazdırır. Eğer bir nesil birden fazla alanın koleksiyonu olarak düzenlenmişse (örneğin, yeni nesil), alana özgü bellek boyutu özeti eklenir.
<JAVA_HOME>/bin/jmap –heap <JAVA_PID>
jcmd
jcmd yardımcı programı, JVM’e tanılama komut istekleri göndermek için kullanılır ve bu istekler Java Flight Record kayitlarini kontrol etmek, JVM ve Java uygulamalarını sorun teşhis ve giderme süreçleri için kullanılır. Java Sanal Makinesi’nin çalıştığı makinede kullanılmalı ve JVM’yi başlatmak için kullanılanlarla aynı etkin kullanıcı ve grup tanımlayıcılarına sahip olmalıdır.
Aşağıdaki komut kullanılarak bir heap bellek dökümü (hprof dökümü) oluşturulabilir:
jcmd <JAVA_PID> GC.heap_dump filename=<FILE>
Yukarıdaki komut şununla aynıdır:
jmap –dump:file=<FILE> <JAVA_PID>
Ancak jcmd kullanılması önerilen araçtır.
jhat
jhat aracı, heap anlık görüntüsündeki nesne topolojisine göz atmak için oldukça kullanışlı bir araçtır. Bu araç, Heap Çözümleme Aracı’nın (Heap Analysis Tool – HAT) yerini alır. Araç, heap dökümünü binary formatta ayrıştırarak (örneğin, jcmd tarafından üretilen bir yığın dökümü seklinde), istenmeyen nesne ilişkisinde hata ayıklamaya yardımcı olabilir.
İstenmeyen nesne ilişkisi terimi, artık gerekli olmayan, ancak kök kümesindeki (rootset) bazı yollardan yapılan başvurular nedeniyle canlı tutulan nesneleri tanımlamak için kullanılır. Bu durum,
- Nesneye ihtiyaç kalmadıktan sonra nesneye yapılan ve artık gerekli olmayan statik bir başvuru kalırsa,
- Bir observer veya listener artık gerekli olmadığında kendisini olay örgüsünden çıkaramazsa veya
- Bir nesneye başvuran bir iş parçacığı gerektiğinde sonlandırılmazsa oluşabilir.
İstenmeyen nesne ilişkisi, bellek sızıntısının Java dilindeki eşdeğeridir.
Aşağıdaki komutla jhat kullanarak heap dump analizi yapabiliriz.
jhat <HPROF_FILE>
Bu komut, kendisine parametre olarak verilen .hprof uzantılı profil dosyasını okur ve 7000 numaralı bağlantı noktasında bir http sunucu başlatır.
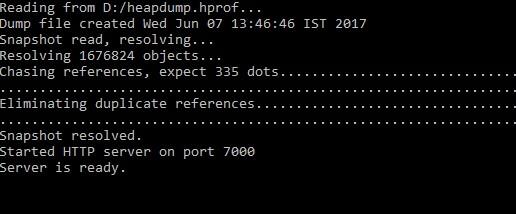
http://localhost:7000 adresini kullanarak sunucuya bağlandığımızda, standart bir sorgu yürütebilir veya bir Nesne Sorgu Dili (OQL) oluşturabiliriz. Varsayılan olarak Tüm Sınıflar sorgusu görüntülenir. Bu varsayılan sayfa, platform sınıfları hariç heap bellekte bulunan tüm sınıfları görüntüler. Bu liste, tam sınıf adına göre sıralanmıştır ve paketlere göre ayrılmıştır. Bir sınıfın adına tıklayarak sınıf sorgusuna gidilebilir. Bu sorgunun ikinci türü platform sınıflarını içerir. Platform sınıfları, tam adları java, sun veya javax.swing gibi öneklerle başlayan sınıfları içerir. Öte yandan, sınıf sorgusu bir sınıf hakkındaki bilgileri görüntüler. Bu bilgi, sorgulanan sınıfın üst sınıfını, tüm alt sınıflarını, örnek veri üyelerini ve statik veri üyelerini içerir. Bu sayfadan referans verilen sınıflardan herhangi birine veya bir instance sorgusuna gidebilirsiniz. Instance sorgusu, belirli bir sınıfın tüm örneklerini görüntüler.
HPROF
HPROF, her JDK sürümüyle birlikte gelen heap ve CPU profili oluşturma aracıdır. Java Virtual Machine Tool Interface (JVMTI) kullanarak JVM ile arayüz oluşturan bir dinamik bağlantı kitaplığıdır (DLL). Araç, profil oluşturma bilgilerini bir dosyaya veya bir sokete ASCII veya binary formatta yazar. HPROF aracı, CPU kullanımını, heap ayırma istatistiklerini ve çekişme profillerini izleme yeteneğine sahiptir. Ayrıca, Java Sanal Makinesi’ndeki (JVM) tüm izleyici ve iş parçacıklarının tüm yığın dökümlerini ve durumlarını raporlayabilir. Sorunları tanılama açısından HPROF, performans, kilit çekişmesi, bellek sızıntıları ve diğer sorunları analiz ederken kullanışlı bir araçtır.
Aşağıdaki komut satırları ile HPROF aracını çağırabiliriz:
java –agentlib:hprof ProfiliOlusturulacakClass
java –agentlib:hprof=heap=sites ProfiliOlusturulacakClass
İstenen profil oluşturma türüne bağlı olarak, HPROF JVM’ye onu ilgili olaylara göndermesi isteğini bildirir. Araç daha sonra olay verilerini profil oluşturma bilgilerine işler. Varsayılan olarak, heap profili oluşturma bilgileri geçerli çalışma dizinindeki java.hprof.txt (ASCII cinsinden) dosyasına yazılır. Aşağıdaki komut
javac –J-agentlib:hprof=heap=sites Hello.java
Hello.java uygulaması için heap ayırma profili elde etmek amacıyla kullanılabilir. Programın çeşitli bölümlerinde görülen ayırma miktarı heap profilinde yer alan önemli bir bilgidir.
Benzer şekilde, heap=dump seçeneği kullanılarak yığın dökümü elde edilebilir.
javac –J-agentlib:hprof=heap=dump Hello.java
Komut satırının çıktısı çöp toplayıcı tarafından belirlenen kök kümesinden ve kök kümesinden erişilebilen heap alanında her Java nesnesi için bulunan girdilerden oluşur.
HPROF aracı, iş parçacıklarını örnekleyerek CPU kullanım bilgilerini toplayabilir. CPU kullanımı örnekleme profili sonuçlarını almak için aşağıdaki komut kullanılabilir:
javac –J-agentlib:hprof=cpu=samples Hello.java
HPROF aracısı, en sık kullanılan etkin yığın izlerini kaydetmek için, çalışan tüm iş parçacıklarının herbirinin stack alanını düzenli aralıklarla örnekler.
Bellek kullanımları, çöp toplama, heap dökümleri, CPU ve bellek profili oluşturma vb. hakkında GUI şeklinde ayrıntılı bilgi sağlayan VisualVM gibi başka araçlar da mevcuttur.
VisualVM
VisualVM, NetBeans platformundan türetilmiş bir araçtır ve mimarisi modüler tasarıma dayanır, yani eklentilerin kullanımıyla genişletilmesi kolaydır. VisualVM, Java uygulamaları bir JVM üzerinde çalışırken onlarla ilgili ayrıntılı bilgi edinmemizi sağlar ve yerel veya uzak bir sistemde çalışan bir uygulama analiz edilebilir. Oluşturulan veriler Java Development Kit (JDK) araçları kullanılarak alınabilir ve birden fazla Java uygulamasındaki tüm veriler ve bilgiler hem yerel hem de uzaktan çalışan uygulamalar için hızlı bir şekilde görüntülenebilir. Java Virtual Machine JVM yazılımı ile ilgili verileri yakalamak ve yerel sisteme kaydetmek de mümkündür. VisualVM, CPU örneklemesi, bellek örneklemesi yapabilir, çöp toplama sürecini başlatabilir, heap hatalarını analiz edebilir, anlık görüntüler alabilir ve daha fazlasını yapabilir.
VisualVM’in Özellikleri
VisualVM, jvmstat, JMX, Serviceability Agent (SA) ve Attach API dahil olmak üzere çeşitli teknolojileri kullanan birçok JVM üreticisinin Java 1.4+ üzerinde çalışan uygulamalarını izler ve bunlarla ilgili sorun tespiti ve giderme imkanları sağlar.
VisualVM, uygulama geliştiricilerin, sistem yöneticilerinin, kalite mühendislerinin ve son kullanıcıların tüm gereksinimlerine eksiksiz şekilde uyum sağlayan bir araçtır.
- Yerel ve Uzak Java İşlemlerini Görüntüleyebilir. VisualVM yerel ve uzakta çalışan Java uygulamalarını otomatik olarak algılar ve listeler (jstatd ajanı uzak ana bilgisayarda çalışıyor olmalıdır). Ayrıca JMX bağlantısı ile uygulamaları manuel olarak tanımlayabilirsiniz.
- Proses Yapılandırmasını ve Ortam Değişkenlerini Görüntüleyebilir. VisualVM her proses için temel runtime bilgilerini gösterir. Bunlar: PID, ana sınıf, Java prosesine iletilen bağımsız değişkenler, JVM sürümü, JDK ana dizini, JVM bayrakları ve bağımsız değişkenler, Sistem özellikleri.
- İşlem Performansını ve Belleği İzleyebilir. VisualVM, uygulama CPU kullanımını, GC etkinliğini, yığın ve metaspace / permgen belleği, yüklenen sınıfların sayısını ve çalışan iş parçacıklarını izler.
- Bir Prosese ait İş Parçacıklarını Görselleştirebilir. Bir Java işleminde çalışan tüm iş parçacıkları, Çalışma, Uyku, Bekleme, Park ve İzleme süreleriyle birlikte bir zaman çizelgesinde toplu olarak görüntülenir.
- İş Parçacıklarına ait Döküm Alabilir ve Görüntüleyebilir. VisualVM, hedef proseste neler olup bittiğine dair anlık bir fikir edinmek için iş parçacığı dökümlerini alır ve görüntüler. Birden çok prosesin eşzamanlı iş parçacığı dökümü, dağıtık kilitlenmelerin (distributed deadlocks) keşfedilmesine yardımcı olur.
- Heap Dökümleri Alabilir ve Döküm içinde Gezinmeyi Sağlayabilir. VisualVM, verimsiz yığın kullanımını ortaya çıkarmaya ve bellek sızıntılarında hata ayıklamaya yardımcı olmak için isteğe bağlı olarak veya OutOfMemoryError sırasında oluşturulan
.hprofbellek anlık görüntülerini oluşturur ve görüntüler.
- Çekirdek Dökümlerini Analiz Edebilir. VisualVM, kilitlenen Java prosesi ve ortamı hakkında temel bilgileri bir çekirdek dökümünden okuyabilir ve içerdiği iş parçacığı ve yığın dökümlerini ayıklayabilir ve açabilir.
- Uygulamaları Çevrimdışı Analiz Edebilir. VisualVM, alınan tüm iş parçacığı dökümleri, yığın dökümleri ve profil oluşturucu anlık görüntüleri ile birlikte uygulama yapılandırmasını ve çalışma zamanı ortamını daha sonra çevrimdışı olarak işlenebilecek tek bir uygulama anlık görüntüsüne kaydedebilir.
JMX Bağlantı Noktalarını Etkinleştirme
Bir Java uygulamasını başlatırken aşağıdaki parametreleri ekleyerek JMX uzak bağlantı noktalarını etkinleştirebilir böylece uygulamanın uzaktan izlenmesini mümkün kılabiliriz:
-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=<Port> -Dcom.sun.management.jmxremote.
Artık uzak makineye bağlanmak ve CPU kullanımını, bellek örneklemesini, iş parçacıklarını vb. görüntülemek için VisualVM’yi kullanabiliriz. JMX Uzak bağlantı noktası üzerinden bağlandığında uzak makinede iş parçacığı dökümleri ve bellek dökümleri de oluşturabiliriz.
Aşağıdaki resimde, yerel ve uzak sistemlerde çalışan uygulamaların listesi görülmektedir. Uzak bir sisteme bağlanmak için, “Remote” düğümüne sağ tıklayarak bir host adı ekleyebilir ve burada bulunan “Advanced Settings” sekmesi altında yer alan, uzak makinede uygulamayı başlatırken kullandığımız port bilgisini tanımlayabiliriz. Local veya remote bölüm altında listelenen uygulamalar olduğunda, üzerine çift tıklayarak uygulamanın ayrıntıları görüntülenebilir.
Uygulamanın ayrıntıları görmek için dört sekme bulunmaktadır. Bunlar: Overview, Monitor, Threads ve Sampler sekmeleri.
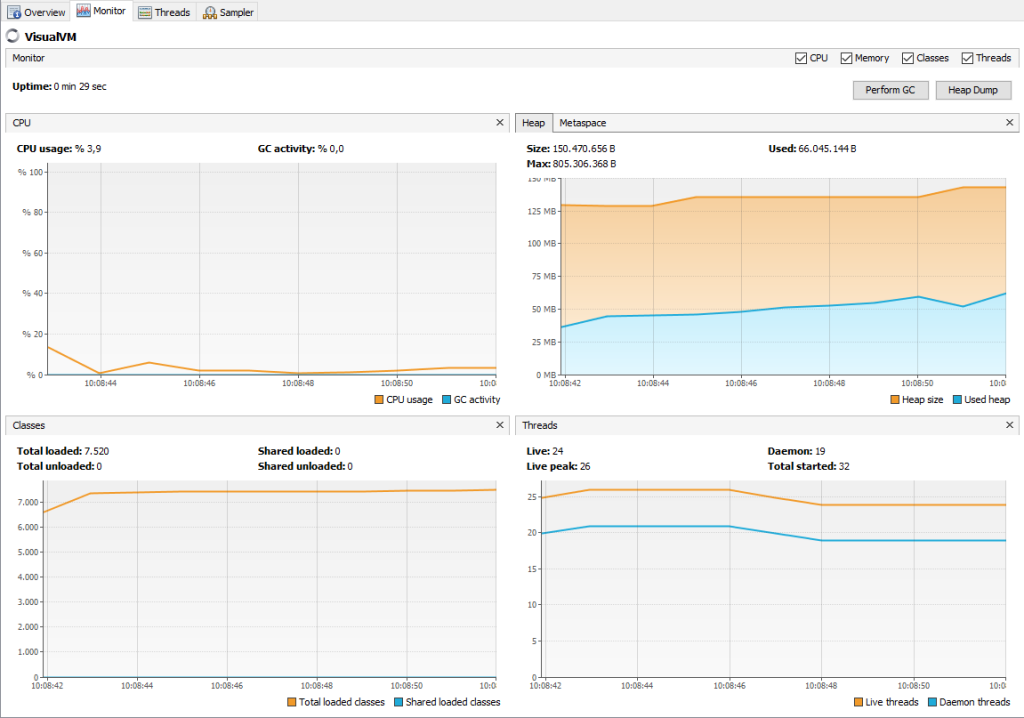
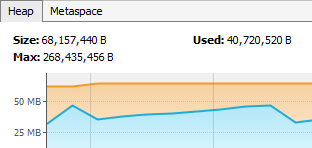
İlk grafik genel CPU kullanımını ve çöp toplayıcı CPU kullanımını gösterir. X ekseni, zamana göre kullanım yüzdesini göstermektedir.
Sağ üstteki ikinci grafik, heap alanını ve Metaspace (veya PermGen) alanını görüntüler. Ayrıca heap alanın maksimum boyutunu, uygulama tarafından ne kadarının kullanıldığını ve ne kadarının kullanıma hazır olduğunu gösterir. Bu grafik, özellikle java.lang.OutOfMemoryError: Java heap alanı hataları ile karşılaşılan uygulamaların analizinde kullanışlıdır. Bir uygulama yoğun bellek kullanan bir iş gerçekleştirirken, kullanılan yığın (grafikte mavi renkle gösterilir) her zaman yığın boyutundan (grafikte turuncu renkle gösterilir) küçük olmalıdır. Kullanılan heap alanı, heap boyutuyla hemen hemen aynı olduğunda veya sistemin heap boyutunu tahsis etmesi/genişletmesi için daha fazla alan kalmadığında ve kullanılan heap alanı artmaya devam ettiğinde, bir yığın hatası ile karşılaşmayı bekleyebiliriz. Heap hakkında daha fazla bilgi “Yığın Dökümü” alınarak elde edilebilir. Yetersiz bellek hatası olduğunda, komut satırına aşağıdaki VM parametreleri eklenerek yığın dökümü elde edilebilir:
-XX:+HeapDumpOnOutOfMemoryError –XX:HeapDumpPath=[dosya yolu]
Bu, belirtilen dosya yolunda bir .hprof dosyasının oluşturulmasını sağlar.
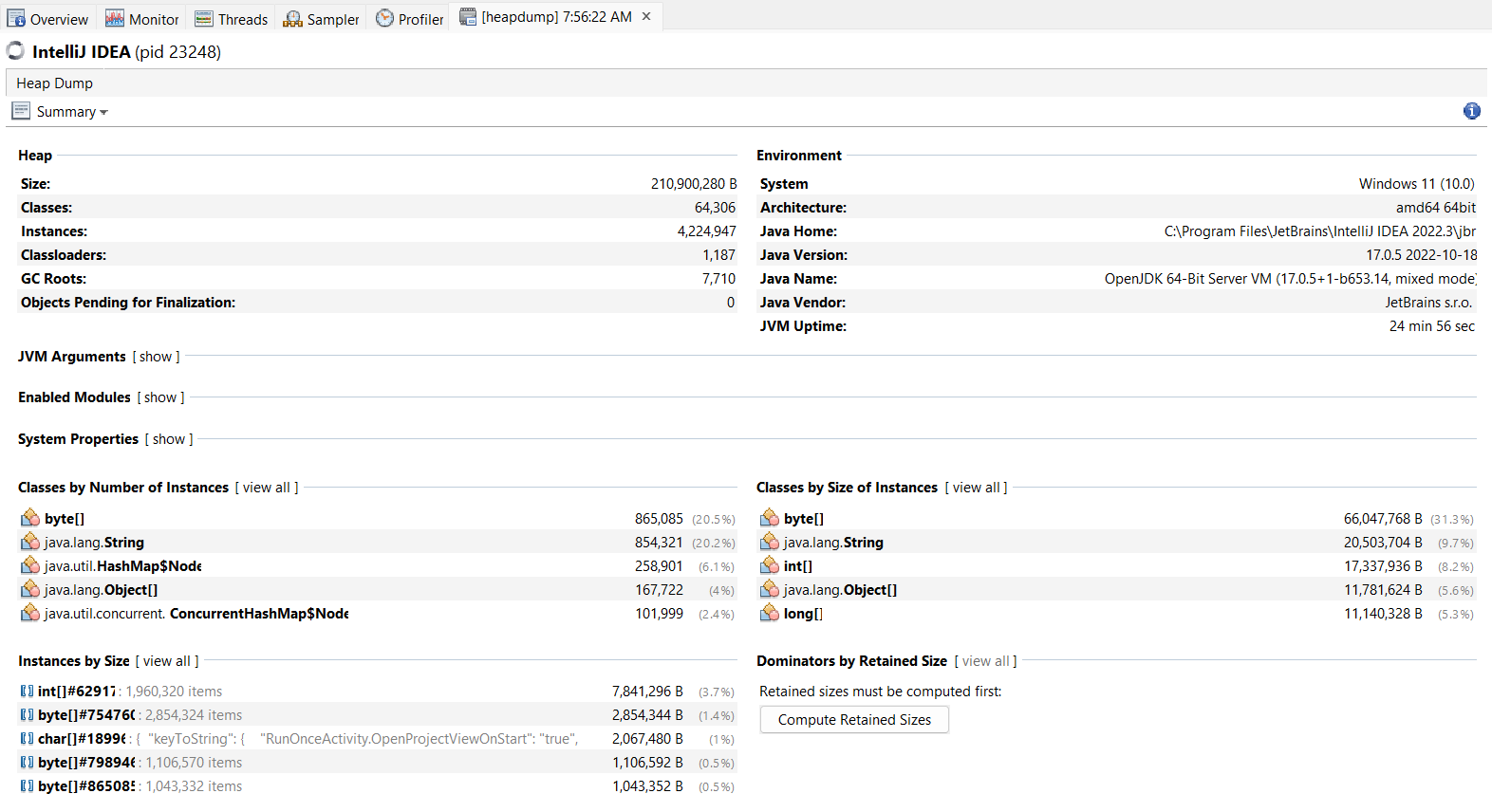
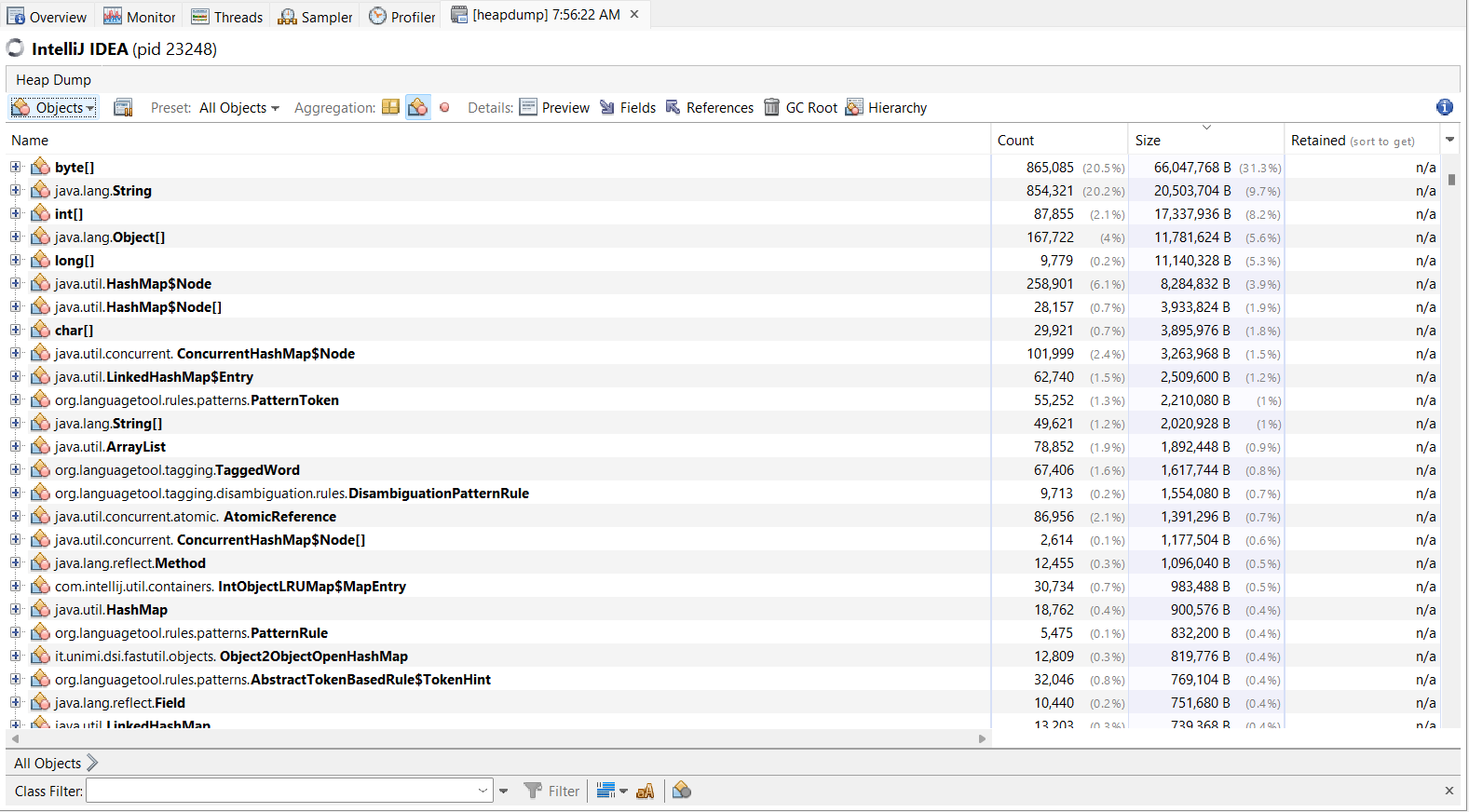
Yukarıdaki iki resimde, VisualVM uygulaması için heap dökümü gösterilmiştir. Summary sekmesinde, uygulamada mevcut toplam sınıf sayısı, bu sınıfların çalışan örneklerinin sayısı, sınıf yükleyicilerinin sayısı, çöp toplayıcıları ve uygulamanın çalıştığı ortam ayrıntıları gibi bazı temel bilgileri görüntüler. Bu analiz heap alanında, en çok hangi tür nesnelerin tahsis edildiğini ve bu tahsisatın nerede gerçekleştiğini gösterir. Büyük nesneler, constructorlarında birçok başka nesne oluşturur veya çok sayıda alana (field/attribute) sahiptir. Burada, production koşulları altında büyük ölçüde eşzamanlı olduğu bilinen kod alanlarını da analiz etmeliyiz. Yük altında, bu konumlara yalnızca daha fazla nesne tahsis edilmekle kalmayacak, aynı zamanda bellek yönetiminin kendi içindeki senkronizasyonunu da artıracaktır. Aşırı çöp toplamanın nedeni yüksek bellek kullanımıdır. Bazı durumlarda, donanım kısıtlamaları, JVM’nin heap boyutunu kolayca artırmayı imkansız hale getirir. Diğer durumlarda, heap boyutunu artırmak sorunu çözmez; yalnızca geciktirir. Cünkü heap kullanım büyümeye devam eder. Yazinin devaminda yapacagimiz analizler, bellek sızıntılarına ait yığın dökümlerinin tanımlanması ve bellek yiyici nesne veya nesnelerin tanımlanması ile mümkündür.
Artık ihtiyaç duyulmayan ancak uygulama tarafından referans verilen her nesne bir bellek sızıntısı olarak kabul edilebilir. Burada, yalnızca büyüyen veya çok fazla bellek kaplayan bellek sızıntılarını önemsiyoruz. Bellek sızıntısı dediğimiz sey aslinda, belirli bir nesne türünün tekrar tekrar oluşturulduğu ancak çöp toplama işleminin yapılmadığı durumdur. Bu nesne türünü tanımlamak için, trend dökümleri kullanılarak karşılaştırılabilecek birden çok yığın dökümü gerekir. Her Java uygulamasında çok sayıda String, char[] ve diğer Java standart nesneleri bulunur. Aslında, String ve char[] nesneleri en yüksek sayıda örneğe sahip nesneler olacaktır, ancak onları analiz etmek bizi hiçbir yere götürmez. String nesnelerini sızdırıyor olsak bile, bunun nedeni büyük olasılıkla sızıntının temelinde bir uygulama nesnesi tarafından referans verilmis olmasidir. Bu nedenle uygulamamızın sınıflarına yoğunlaşmak daha hızlı sonuç verecektir.
Asagidaki durumlarda ayrintili bir analiz gerekebilir:
- Trend analizi sonucunda bellek sızıntısıni yakalayamadiysak.
- Uygulamamız çok fazla bellek kullandigi halde belirgin bir bellek sızıntısı goremedik ve kodu optimize etmemiz gerekiyorsa.
- Bellek çok hızlı büyüdüğü ve JVM çöktüğü için trend analizi yapamadıysak.
Her üç durumda da temel neden, büyük olasılıkla daha büyük bir nesne ağacının kökünde bulunan bir veya daha fazla nesnedir. Bu nesneler, ağaçtaki diğer birçok nesnenin çöp toplanmasını engeller. Yetersiz bellek hatası durumunda, böyle az sayıda nesnenin, çok sayıda nesnenin bellekten atılmasını engellemesi ve dolayısıyla yetersiz bellek hatasını tetiklemesi muhtemeldir. Heap boyutu genellikle bellek analizi için büyük bir sorundur. Heap dökümü oluşturmak, belleğin kendisini gerektirir. Yığın boyutu, mevcut veya olası olanın sınırındaysa (32 bit JVM’ler 3,5 GB’den fazlasını ayıramaz), Java Sanal Makinesi (JVM) bir tane oluşturamayabilir. Ayrıca, bir yığın dökümü JVM’yi askıya alacaktır. Tüm bir nesne ağacının çöplerin hızla toplanmasını önleyen tek nesneyi manuel olarak bulmak, samanlıktaki atasözü iğnesi haline gelir.
Neyse ki Dynatrace gibi çözümler bu nesneleri otomatik olarak tanımlayabiliyor. Bunu yapmak için graf teorisinden kaynaklanan bir baskın algoritma kullanmamız gerekiyor. Bu algoritma, bir nesne ağacının kökünü hesaplayabilmelidir. Bellek analiz aracı, nesne ağacı köklerini hesaplamaya ek olarak, belirli bir ağacın ne kadar bellek tuttuğunu da hesaplar. Bu şekilde, hangi nesnelerin büyük miktarda belleğin serbest bırakılmasını engellediğini – başka bir deyişle, hangi nesnenin belleğe hükmettiğini hesaplayabilir.
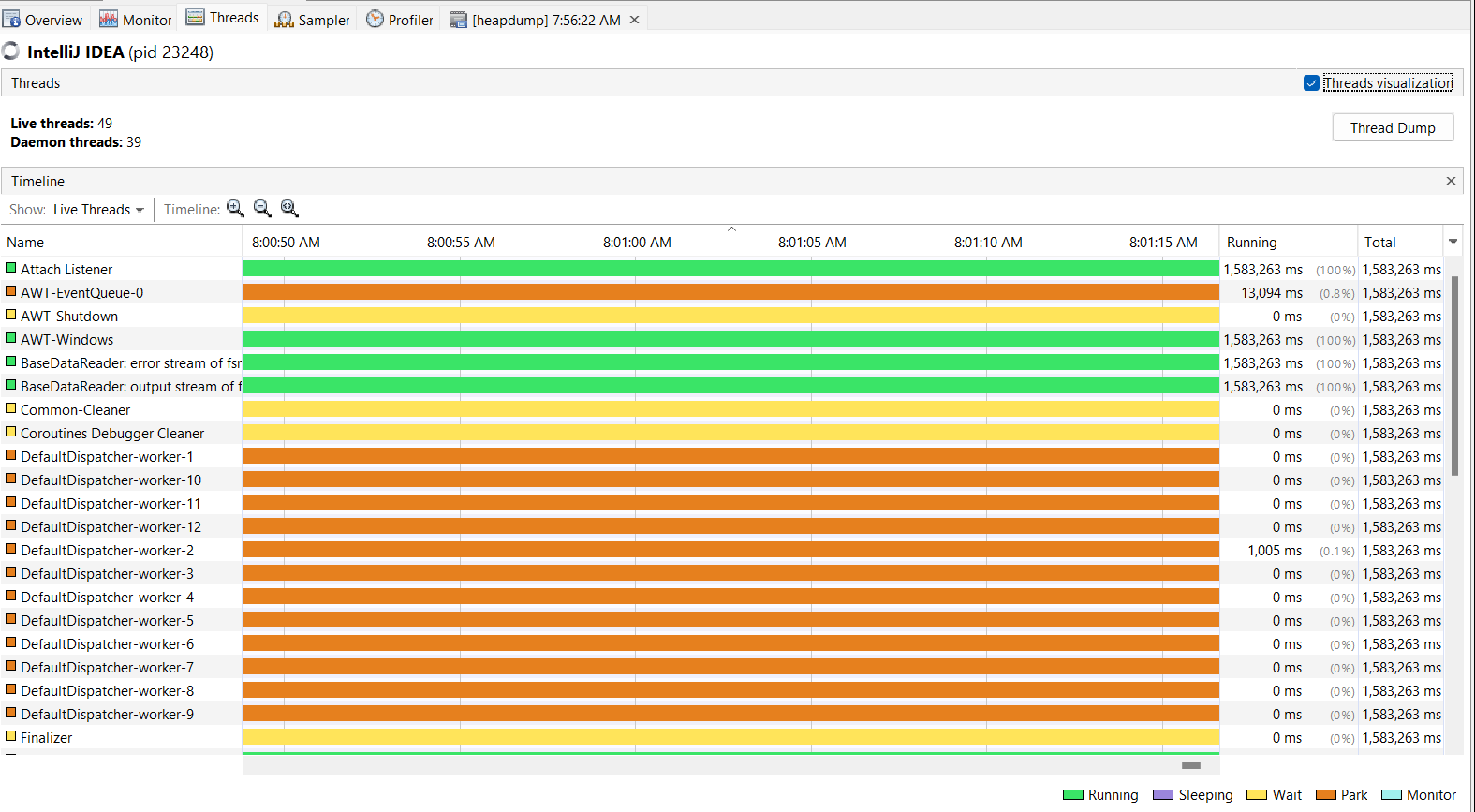
Monitor sekmesi altındaki bir uygulama için mevcut grafiklere geri dönersek, sol altta yer alan sınıflar grafiğidir. Bu grafik, uygulamada yüklenen toplam sınıf sayısını gösterir ve son grafik, o anda çalışmakta olan iş parçacığı sayısını gösterir. Bu grafiklerle uygulamamızın çok fazla CPU mu yoksa bellek mi aldığını görebiliriz.
Üçüncü sekme Threads (İş Parçacıkları) sekmesidir.
Bu sekmede uygulamanın farklı iş parçacıklarının nasıl durum değiştirdiğini ve nasıl geliştiğini görebiliriz. Ayrıca her durumda geçen süreyi ve iş parçacıklarıyla ilgili birçok detayı da gözlemleyebiliyoruz. Yalnızca canlı iş parçacıklarını veya biten iş parçacıklarını görüntülemek için filtreleme seçenekleri mevcuttur. Bir iş parçacığı dökümüne ihtiyacımız varsa, üstteki “Thread Dump” butonunu kullanarak bunu elde edebiliriz.
Dördüncü sekme Sampler sekmesidir.
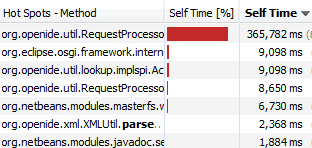
Bu sekmeyi ilk açtığımızda hiçbir bilgi içermediğini görebiliriz. Bu yüzden burada öncelikle bir örnekleme (ya da profil) oluşturmamız gerekiyor. CPU örneklemesiyle başlayalım. “CPU” düğmesine tıkladıktan sonra CPU örneklemesinin sonuçları tabloda görüntülenir.
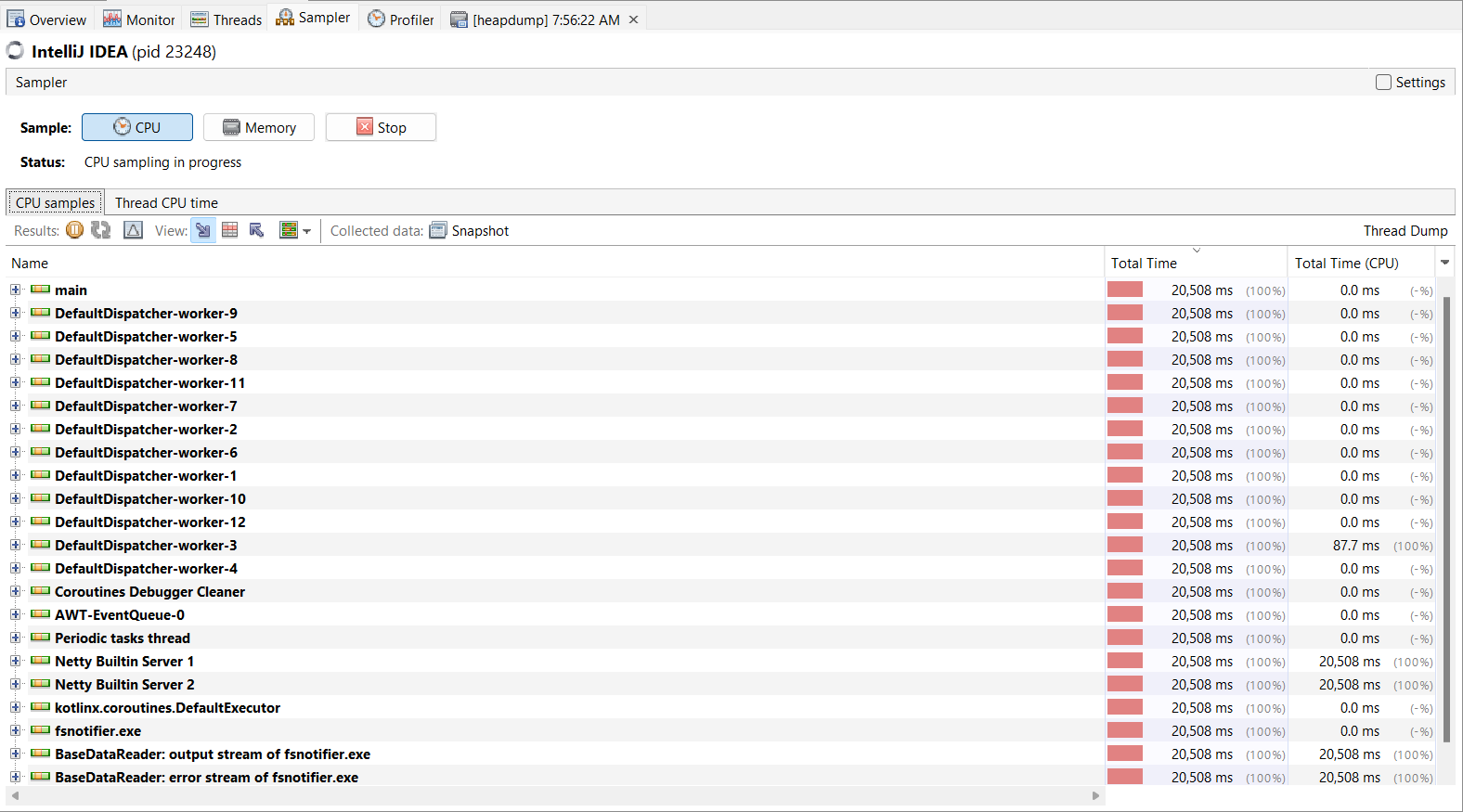
Burada CPU zamaninin uygulama tarafindan nasil tuketildigini gorebiliriz. CPU ile ilgili bir darbogaz olustugu durumlarda bu analiz oldukca faydali olabilir. Yukaridaki resimde IntelliJ IDEA idesi icin bir CPU profili olusturulmus ve toplam CPU zamaninin ne kadarinin kullanildigi ayrintili olarak listelenmistir.
Bir sonraki örnekleme Bellek örneklemesidir. Uygulama, sonuçlar alınana kadar örnekleme sırasında dondurulacaktır. Asagidaki ekran alintisindan gorulecegi uzere uygulamanın verileri cogunlukla byte[], int[], Object[], long[] dizileri ve String nesnesi seklinde sakladığı sonucunu çıkarabiliriz.
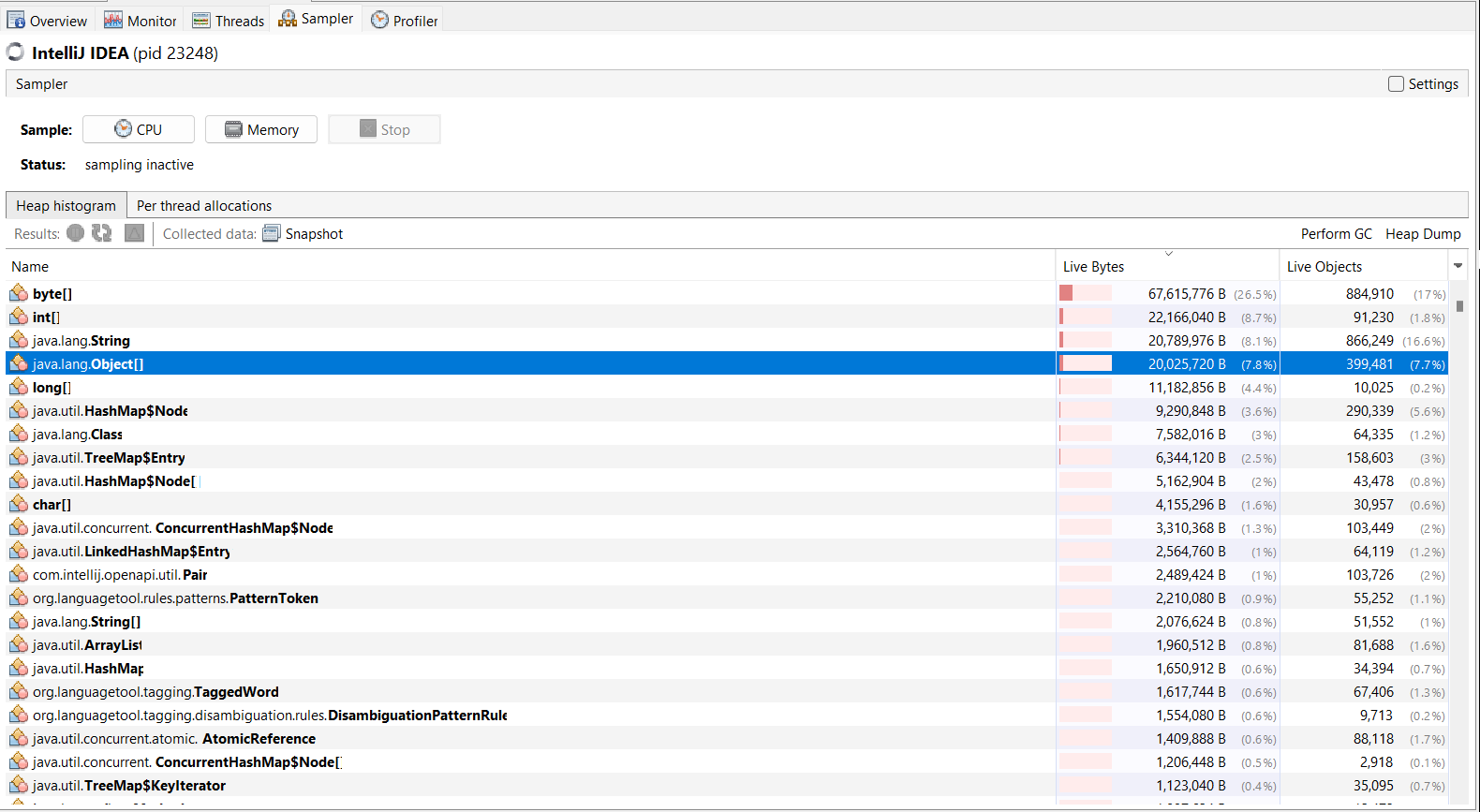
Her iki örnekleme türünde de sonuçları daha sonra kullanmak üzere bir dosyaya kaydedebiliriz. Örneğin belirli aralıklarla birden çok kez numune alınabilir ve sonuçlar karşılaştırılabilir. Boylece, uygulamayı daha az CPU ve bellek kullanacak şekilde geliştirebiliriz. Son olarak bu alanları incelemek ve kodu geliştirmek geliştiricinin görevidir.
Java’nın Bellek Modeli
Metaspace
Java 8 ile birlikte Perm Gen kaldırılmış olup, bu da artık “java.lang.OutOfMemoryError: PermGen” alan sorununun olmayacağı anlamına gelir. Metaspace, heap alanında bulunan Perm Gen alanından farklı olarak, heap alanın bir parçası değildir. Metaspace ile birlikte sınıf meta verilerine ayrılan çoğu alan artık native bellekten ayrılmaktadır. Metaspace varsayılan olarak boyutunu, işletim sisteminin sağladığı kadarıyla, otomatik olarak artırır. Ancak Perm Gen her zaman sabit bir boyuta sahiptir. Metaspace’in boyutunu ayarlamak için iki tane komut satırı parametresi vardır. Bunlardan ilki “-XX:MetaspaceSize” ve diğeri “-XX:MaxMetaspaceSize” parametresidir. Metaspace’in arkasındaki mantık, sınıfların ve meta verilerinin yaşam süresinin, sınıf yükleyicilerin yaşam süresiyle aynı olmasını sağlamaktır. Yani, sınıf yükleyici bellekte var olduğu sürece meta veriler de Metaspace’teki bellekte var olur ve silinemez.
Permanent Generation
Java 8’den itibaren adı Metaspace olarak değiştirilen Permanent Generation veya “Perm Gen” alanı, uygulamada kullanılan sınıfları ve metotları tanımlamak için JVM’nin ihtiyaç duyduğu uygulama meta verilerini içerir. Perm Gen, uygulama tarafından kullanılan sınıflara dayalı olarak çalışma zamanında JVM tarafından doldurulur. Perm Gen ayrıca Java SE kütüphane sınıflarını ve metotlarını da içerir.
Code Cache (Kod Önbelleği)
Bir Java programı çalıştırıldığında, kod katmanlı bir şekilde yürütülür. İlk katmanda, kodu derlemek için istemci derleyicisi (C1) kullanılır. İkinci katmanda ise sunucu derleyicisi (C2) vardır. Sunucu derleyici bu kodu optimize edilmiş bir şekilde derlemek için profil verilerini kullanır. Katmanlı derleme, Java 7’de varsayılan olarak etkin değildir, ancak Java 8’de etkinleştirilmiştir.
Just-In-Time (JIT) derleyicisi, derlediği kodu kod önbelleğinde depolar. Burası derlenmiş kodun tutulduğu özel bir heap alanıdır. Boyutu belli bir eşiği aşarsa bu alan temizlenir ve bu temizlenen nesneler GC tarafından yeniden yerleştirilmez.
Bazı performans sorunları ve derleyicinin yeniden etkinleştirilmemesi sorunu Java 8’de ele alınmıştır ve Java 7’de bu sorunları önlemenin çözümlerinden biri, kod önbelleğinin boyutunu asla ulaşılmayacak bir noktaya kadar artırmaktır.
Method Area (Metot Alanı)
Metot Alanı, Perm Gen’in bir parçasıdır ve sınıf yapısını (çalışma zamanı sabitleri ve statik değişkenler), metotlar ve constructorlara ait kodları depolamak için kullanılır. Bu alan Metot ve kurucu metot alan verileri ve sınıfta kullanılan arabirimler (interface) veya özel metotlar için ayrılmıştır. JVM’in başlangıcında oluşturulur.
Memory Pool (Bellek Havuzu)
Bellek Havuzları, değişmez (literal) nesnelerden oluşan bir havuz oluşturmak için JVM bellek yöneticileri tarafından oluşturulur. Bellek Havuzu, JVM bellek yöneticisi uygulamasına bağlı olarak Heap veya Perm Gen alanına ait olabilir.
Run-Time Constant Pool (Çalışma Zamanı Sabit Havuzu)
Çalışma zamanı sabit havuzu, her bir sınıf için bir sınıftaki sabit havuzun çalışma zamanı temsilidir. Sınıf çalışma zamanı sabitlerini ve statik yöntemleri içerir. Çalışma zamanı sabit havuzu, metot alanının bir parçasıdır.
Heap Alanı ile ilgili Komut Satırı Parametreleri
Java, calistirilan uygulamanin kullanacagi bellek boyutlarını ve oranlarını ayarlamak için kullanabileceğimiz, bellekle ilgili birçok parametre sağlar. Yaygın olarak kullanılan parametrelerden bazıları şunlardır:
-Xms : JVM başladığında başlangıç heap boyutunu ayarlamak için kullanılır.
-Xmx : Maksimum heap boyutunu ayarlamak için kullanılır.
-Xmn : Yeni nesil nesne alanı boyutunu ayarlamak için kullanılır. Alanın geri kalanı eski nesil nesne alanı olarak tahsis edilir.
-XX:PermGen : Perm Gen belleğin başlangıç boyutunu ayarlamak için kullanılır.
-XX:MaxPermGen : Perm Gen’in maksimum boyutunu ayarlamak için kullanılır.
-XX:SurvivorRatio : Eden ve survivor alanlarının kullanım oranını belirlemek için kullanılır. Örneğin, genç nesil nesne alanı boyutu 10m ve –XX:SurvivorRatio=2 ise, Eden alanı için 5m ve Survivor alanlarının her biri için 2.5m ayrılacaktır. Varsayılan değer 8’dir.
-XX:NewRatio : Eski/yeni nesil nesne alanları boyutlarının oranını ayarlamak için kullanılır. Varsayılan değer 2’dir.
Java’da Bellek Kullanımı ve Yönetimine Dair Öneriler
- Bellek ayak izini en aza indirmek için değişkenlerin kapsamını mümkün olduğunca sınırlandırın. Stack alanının üst kapsamından yapılan her pop işleminin, bu kapsamdaki referansları kaybedeceğini ve bunun da bu referansların gösterdiği nesneleri çöp toplama için uygun hale getirebileceğini unutmayın.
- Eskimiş olan referanslara
nullreferans gösterin. Böylece, referans gösterilen nesneler çöp toplama için uygun hale gelecektir. - Sonlandırıcılardan (Terminator/Deconstructor) kaçının. Isleri yavaşlatırlar ve hiçbir şeyi garanti etmezler. Temizleme çalışmaları için hayalet referansları tercih edin.
- Zayıf veya yumuşak referansların olduğu durumlarda güçlü referanslar kullanmayın. En yaygın bellek tuzakları, gerekli olmasa bile, verilerin bellekte tutulduğu önbelleğe alma senaryolarıdır.
- Ayrıca VisualVM belirli bir noktada yığın dökümü yapma işlevine sahiptir. Böylece uygulamanın sınıf başına ne kadar bellek kapladığını analiz edebilirsiniz.
- JVM’nizi uygulama gereksinimlerinize göre yapılandırın. Uygulamayı çalıştırırken JVM için gereken heap boyutunu açıkça belirtin. Bellek ayırma işlemi de pahalı bir süreçtir. Bu nedenle heap için makul bir başlangıç ve maksimum bellek miktarı ayırın. Başlangıçtan itibaren küçük bir başlangıç yığını boyutuyla başlamanın mantıklı olmayacağını biliyorsanız, JVM bu bellek alanını verdiğiniz maksimum bellek miktarına ulaşıncaya kadar genişletecektir. Java’da bellekle ilgili seçenekleri aşağıdaki komut satırı parametreleri ile belirtebilirsiniz:
- Başlangıç heap boyutu
-Xms512m– başlangıç heap boyutunu 512 megabayt olarak ayarlar. - Maksimum heap boyutu
-Xmx1024m– maksimum heap boyutunu 1024 megabayt olarak ayarlar. - İş parçacığı (thread) stack boyutu
-Xss1m– iş parçacığı (thread) stack boyutunu 1 megabayt olarak ayarlar. - Genç nesil alan boyutu
-Xmn256m– genç nesil alan boyutunu 256 megabayt olarak ayarlar.
- Başlangıç heap boyutu
- Bir Java uygulaması
OutOfMemoryErrorhatası ile çökerse ve sorunu tespit etmek için bazı ek bilgilere ihtiyacınız varsa, işlemi–XX:HeapDumpOnOutOfMemoryparametresiyle çalıştırabilirsiniz. Bu parametre bir dahaki sefere bu hata olduğunda bir heap döküm (dump) dosyası oluşturur. - Çöp toplama çıktısını almak için
-verbose:gckomut satırı seçeneğini kullanın. Her çöp toplama işlemi gerçekleştiğinde, bir çıktı oluşturulur.
Programın ve verilerinin nasıl saklandığını veya düzenlendiğini bilmek, programcının kaynaklar ve bu kaynakların tüketimi açısından optimize edilmiş bir kod yazmak istediğinde yardımcı olması açısından önemlidir. Ayrıca bellek sızıntılarını veya tutarsızlıklarını bulmaya yardımcı olur ve bellekle ilgili hataların ayıklanmasına yardımcı olur. Bununla birlikte, bellek yönetimi kavramı son derece geniştir ve bu nedenle kişi, bu konudaki bilgisini geliştirmek için mümkün olduğunca çok çalışmalı, elinden gelenin en iyisini yapmalıdır.
Kaynaklar
- Java Memory Management for Java Virtual Machine (JVM) | Betsol – https://www.betsol.com/blog/java-memory-management-for-java-virtual-machine-jvm/
- Java Memory Management – GeeksforGeeks – https://www.geeksforgeeks.org/java-memory-management/
- Master Guide to Java Memory Management – DZone Java – https://dzone.com/articles/java-memory-management
- Memory Management in Java – Javatpoint – https://www.javatpoint.com/memory-management-in-java
- JRockit – Wikipedia – https://en.wikipedia.org/wiki/JRockit
- Java Garbage Collection Basics – https://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html
- How the JVM uses and allocates memory | Red Hat Developer – https://developers.redhat.com/articles/2021/09/09/how-jvm-uses-and-allocates-memory
- VisualVM: Features – https://visualvm.github.io/features.html
İlk Yorumu Siz Yapın